Intégrez la Suite OKA à votre cluster AWS
Gérer efficacement une infrastructure HPC est complexe et souvent dépourvu des outils appropriés pour suivre et obtenir des insights sur le comportement des utilisateurs ainsi que sur la réactivité du cluster face à la demande. Cette complexité est encore accrue lors de l’utilisation de clusters Cloud. En raison de leur nature transitoire et dynamique, les informations sur les types d’instances, l’emplacement et les coûts sont des éléments importants à surveiller, surtout lorsque vous payez pour l’utilisation.
La tâche de gérer et de présenter ces métriques devient de plus en plus difficile à mesure que l’infrastructure grandit ou subit des changements au fil du temps, ce qui est une situation courante dans les environnements Cloud.
Les métriques et les informations « standard » fournies par le planificateur de tâches pourraient ne pas suffire pour gérer efficacement les clusters Cloud. Par exemple, le suivi des coûts d’exécution des tâches devient encore plus important pour surveiller et gérer votre budget, ainsi que pour redistribuer les coûts aux utilisateurs ou aux départements. En raison de la grande variété de types d’instances de calcul dans le Cloud, il peut également être intéressant de suivre sur quels types d’instances les tâches ont été exécutées, afin de vérifier leurs performances et les coûts associés, et d’améliorer davantage le placement et la sélection des instances pour les tâches.
OKA offre de nombreux avantages pour surveiller vos tâches et plonger en profondeur dans le comportement de vos clusters ainsi que dans leur utilisation par vos utilisateurs finaux. Accéder aux informations sur le Cloud dans OKA est simple, à condition d’avoir configuré votre environnement correctement. Dans cet article, nous présentons une intégration simple qui peut être réalisée dans un cluster Slurm sur AWS pour récupérer le type d’instances sur lesquelles s’exécutent les tâches, leurs informations tarifaires (à la demande/instance spot, prix par heure…), la région AWS et pratiquement toutes les informations concernant l’environnement AWS que vous utilisez.
Les scripts fournis ci-dessous sont donnés à titre d’exemples, et peuvent facilement être adaptés pour récupérer des informations plus détaillées ou pour fonctionner avec d’autres planificateurs de tâches (par exemple, LSF, PBS…).
Il existe de nombreuses façons de créer un cluster sur AWS, les détails sortent du champ d’application de cet article, mais vous pouvez par exemple utiliser AWS ParallelCluster ou CCME.
Note : la solution présentée ici est extraite de CCME où elle est disponible prête à l’emploi.
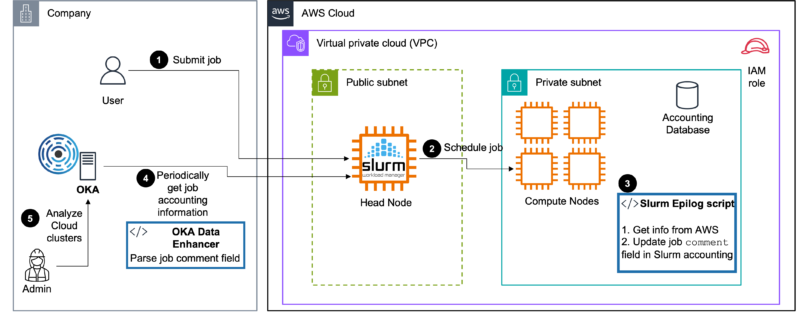
Le principe décrit ici est très simple et repose sur deux composants :
- Un Slurm epilog script qui collectera des informations sur l’environnement AWS sur lequel la tâche s’exécute et stockera ces informations sous forme de valeurs séparées par des virgules (CSV) dans le champ Comment de la tâche. Les informations collectées sont les suivantes :
- instance type
- instance id of the « main » job node
- availability zone
- region
- instance price
- cost type: ondemand or spot
- tenancy: shared, reserved…
- Un Data Enhancer OKA qui analysera les valeurs du champ
Commentet les stockera en tant qu’informations supplémentaires pour chaque tâche.
Le principe décrit ici peut également être facilement adapté à d’autres fournisseurs Cloud. Par exemple, vous pourriez suivre les indications présentées dans l’intégration d’Azure avec Slurm présentée ici dans la section « Granular Cost Control ».
Script Slurm epilog
Ce script Slurm epilog récupère des informations sur le type d’instance et son tarif lorsque la tâche se termine, et stocke les informations dans le champ Comment de la tâche dans sacct. Les commentaires fournis par l’utilisateur sont conservés, et les informations sont ajoutées à la fin après un point-virgule. Le format du champ Comment est le suivant :
Les packages suivants sont nécessaires et doivent être disponibles sur chaque noeud du cluster :
Notez également que cette solution nécessite que Slurm soit configuré pour conserver des informations comptables sur les tâches. Consultez la documentation Slurm pour configurer la comptabilité manuellement, ou si vous utilisez AWS ParallelCluster, vous pouvez suivre ce guide ce guide.
Lorsque l’epilog script contacte les API AWS pour collecter les informations, il doit s’exécuter sur des instances ayant (au minimum) la politique suivante attachée au rôle de l’instance:
Script
Installation
- Copiez le script epilog sur un dossier accessible par tous les noeuds, e.g.,
/shared_nfs/slurm/slurm-epilog.sh, et donnez lui des droits d’exécution:chmod +x /shared_nfs/slurm/slurm-epilog.sh - Editez
/etc/slurm/slurm.conf(sur tous les noeuds), et paramétrez l’optionEpilogen/shared_nfs/slurm/slurm-epilog.sh - Reconfigurez les daemons Slurm :
scontrol reconfigure, ou redémarrez-les:systemctl restart slurmd
Ensuite soumettez un job. Une fois terminé, vérifiez que l’output de sacct dans le champs Comment est bien l’output attendu : sacct --format "jobid,comment".
OKA Data Enhancer
Un Data Enhancer doit être créé et configuré dans OKA afin de traiter les données supplémentaires collectées par le script d’épilogue Slurm. Nous proposons ici un exemple de Data Enhancer que vous pouvez adapter à vos besoins (le commentaire inclus la génération de données « fictives » si vous souhaitez d’abord le tester) :
Installation
Veuillez vous référer à la section Data Enhancer pour des explications sur la manière d’installer et de configurer ce Data Enhancer dans le pipeline d’ingestion.
Accédez à vos informations AWS dans OKA
Les informations récupérées via le Data Enhancer sont ensuite disponibles dans OKA à travers plusieurs plugins et filtres.
Nous présentons ci-dessous quelques exemples d’endroits où les informations peuvent être consultées et utilisées pour analyser vos charges de travail :
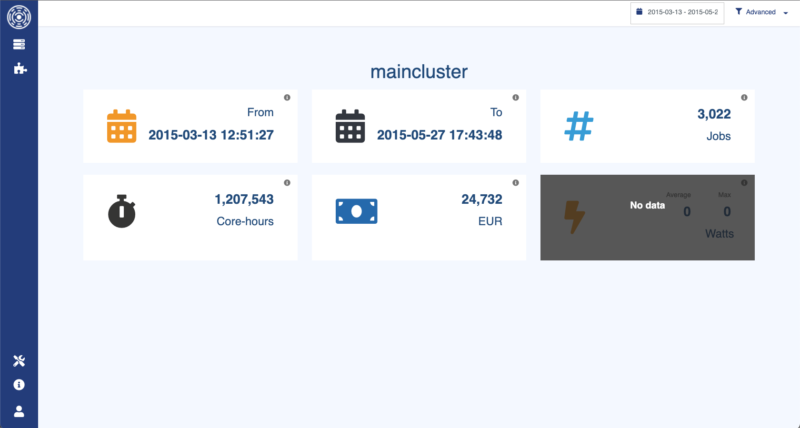
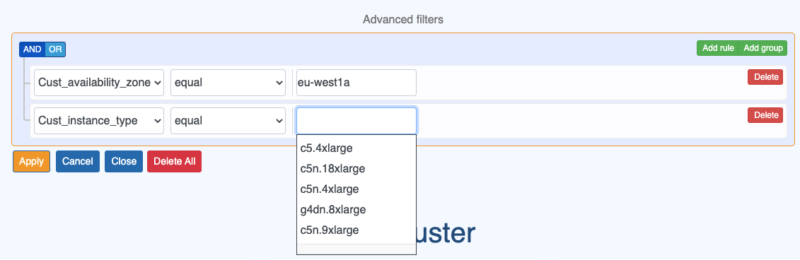
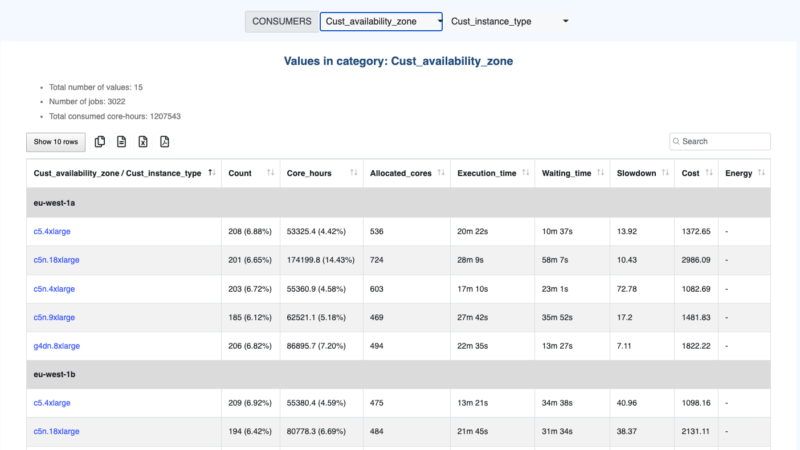
Detailed information in Plugin Consumers
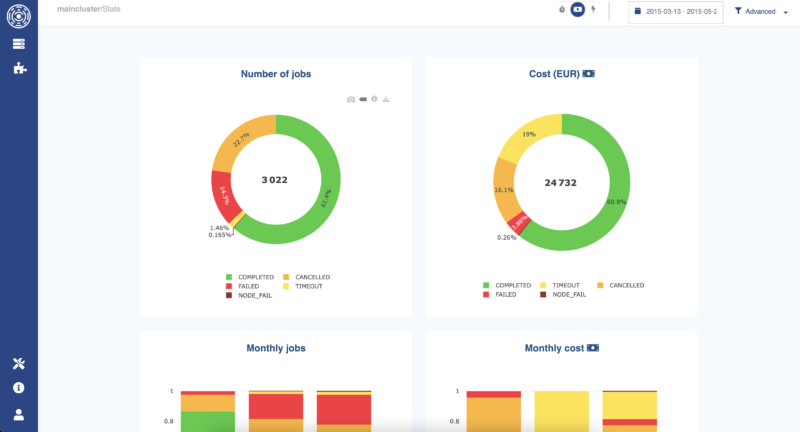
Cost per job status in Plugin State to detect waste.
Conclusion
Cet article a présenté une approche d’intégration simple pour un cluster Slurm sur AWS. En exploitant un script d’épilogue Slurm et un Data Enhancer OKA, des informations précieuses sur l’environnement AWS peuvent être récupérées et analysées.
En utilisant les informations AWS intégrées dans OKA, les administrateurs ont accès à divers plugins et filtres pour analyser et visualiser les charges de travail. Cela permet une meilleure gestion des coûts, un contrôle plus granulaire et l’identification de pratiques inefficaces.
Dans l’ensemble, l’intégration d’un cluster AWS avec OKA permet aux administrateurs d’optimiser leur infrastructure HPC, d’obtenir des informations sur l’utilisation des ressources et les coûts, et de prendre des décisions basées sur les données pour une gestion efficace des clusters dans les environnements cloud.