Hackathon EUMASTER4HPC July 2023
At the heart of this Hackathon, the modern Cloud HPC panorama & challenges
In today’s HPC landscape, efficiently using Cloud HPC resources requires a multifaceted approach. Users must identify suitable workloads for the Cloud, create tailored cloud HPC clusters, and manage these environments smartly. The 2023 EUMaster4HPC Summer School Hackathon exemplifies these challenges, offering participants hands-on experience in workload selection, cluster customization, and orchestration. This event mirrors the broader HPC landscape, preparing individuals to excel in the Cloud HPC era. As technology advances, such hackathons become pivotal in shaping high-performance computing’s future.

The EUMaster4HPC Hackathon
From July 24th to July 28th, 2023, the 1st EUMaster4HPC Summer School Hackathon unfolded at Grenoble INP – Ensimag, France. It brought together 25 talented students from across Europe. Their mission: to port the GEOSX simulation framework (a collaborative endeavor by TotalEnergies, Lawrence Livermore National Laboratory, and Stanford University) onto AWS EC2 Hpc7g using Arm tools. Supported by AWS and an extensive partner network including NVIDIA, UCit, Arm, and SiPearl, this hackathon marked a significant milestone in the convergence of HPC and cloud computing. Under the banner of EUMaster4HPC, an HPC European consortium at the forefront of HPC education, this event showcased the fusion of academia and industry, demonstrating the immense potential of HPC in the cloud. With Amazon Web Services (AWS) as a key participant, this hackathon ushered in a new era of collaborative innovation. Students immersed themselves in GEOSX and benchmarking suites, culminating in presentations of their results and invaluable feedback. UCit’s HPC Cloud solutions, running on AWS, provided dedicated HPC resources for each of the five teams, while GEOSX found a new home on AWS ARM Graviton3, a testament to effective porting and the power of partnership. While challenges persisted, students’ enthusiasm and the support of AWS and its partners prevailed, making this hackathon a resounding success, thanks to the dedicated efforts of Kevin Tuil, Conrad Hillairet, Benjamin Depardon, Jorik Remy, and Francois Hamon.
GEOSX, an innovative carbon storage simulation tool that had never been ported to an ARM architecture
GEOSX is a cutting-edge open-source software designed to address the critical challenge of carbon dioxide (CO2) storage, a key aspect of combatting climate change. It serves as a powerful tool for modeling and simulating the subsurface processes related to CO2 storage. It aids in creating detailed well designs for CO2 injection by considering factors such as well composition, rock characteristics, and potential fluid leakage pathways. Furthermore, GEOSX helps predict how fluids flow and rocks break deep underground, offering 3D behavioral predictions of underground reservoirs, essential for assessing their suitability for long-term CO2 storage. By breaking down simulations into manageable sections, GEOSX can tackle large-scale underground modeling, enabling predictions spanning seconds to thousands of years into the future. Its open-source nature and platform portability make it accessible for a wide range of users, from standard laptops to supercomputers and exascale platforms. GEOSX represents a critical step towards developing effective CO2 sequestration solutions and advancing our transition to a low-carbon future.

GEOSX simulation of the fluid pressure distribution in a faulted reservoir due to CO2 injection. GEOS provides a framework for modeling complex flow and geomechanical processes on next generation computing architectures. Credit: Geologic data courtesy Gulf Coast Carbon Center.
The teams’ mission
The students were working in teams of 5. The hackathon was not a competition between the teams, its goal was to allow the students to discover what it meant to be an HPC engineer and let them face the same kind of issues and challenges that they will face when dealing with a new code on a new HPC platform.
So, the target was threefold:
- Discover the AWS Cloud environment,
- Test and benchmark an ARM-based HPC cluster in AWS, with the last generation of AWS Graviton 3 processors,
- Compile and run simulations with the GOESX application.
The hackathon was organized on 1 week organized as follows:
- 1 day of introduction of ARM ecosystem and the AWS platform
- 3 days of hands-on
- Last day for results presentation
Very short period to reach all the targets, but all teams performed very well and delivered a tremendous amount of work. Congratulations to them all.
A fully featured ARM HPC Cluster on AWS
Providing an HPC platform to the students has been easy: we relied on our CIAB (Cluster-in-a-Box) offering to setup a complete HPC environment in a dedicated AWS account. CIAB relies on our CCME solution (Cloud Cluster Made Easy) that automates the deployment of HPC clusters on AWS.
For the sake of the Hackathon, here is the high-level view of what has been deployed:
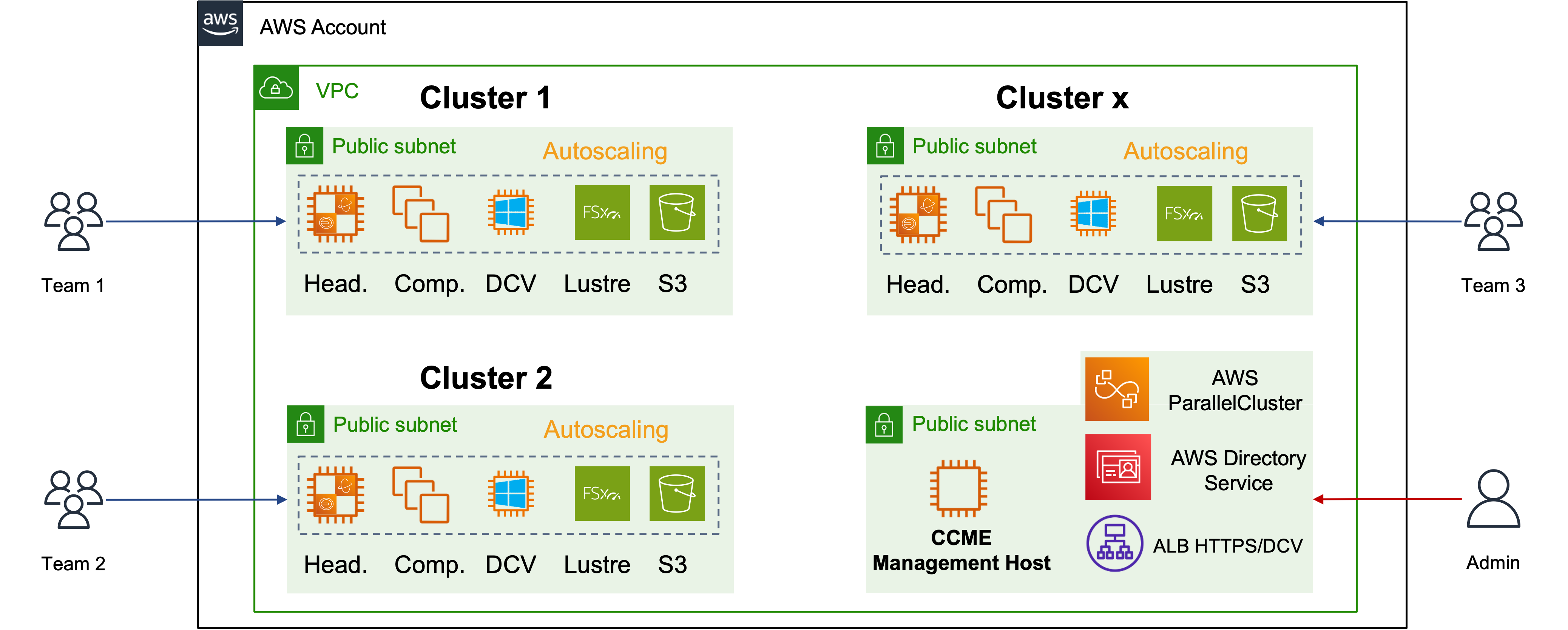
High-level architecture of the Hackathon HPC platform deployed in CIAB.
The whole HPC platform has been deployed in AWS Region North Virginia (us-east-1), in order to have sufficient hpc7g capacity (we had created a Capacity Reservation prior to the Hackathon, to ensure availability of the instances during the week).
Each cluster is fully isolated from the others (network, accounts…), so even if this wasn’t a competition, students couldn’t go to another team’s cluster to interfere with it. Each cluster had the following configuration:
- Job scheduler: SLURM
- Head node: running on a c7g.4xlarge (16vCPUs – AWS Graviton 3, 32GiB)
- Compute nodes: 10 hpc7g.16xlarge (64 vCPUs – AWS Graviton 3, 128 GiB) instances (dynamically launched when needed) were available on each cluster, providing up to 640 vCPUs to the team.
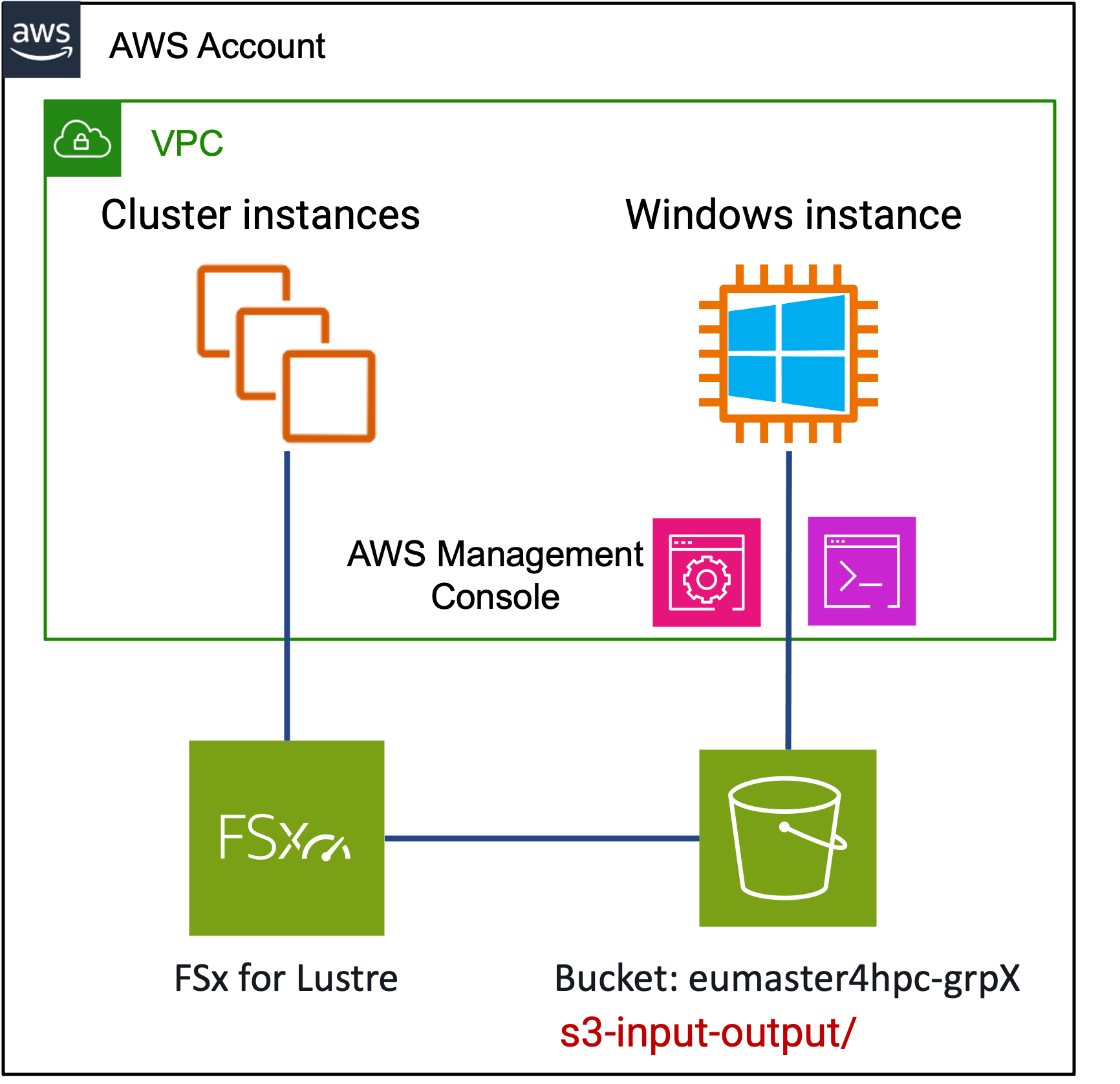
- Storage: a shared NFS supports the homes with only 500GiB, complemented by a parallel file system: FSx for Lustre of 1.2TiB as scratch storage. The FSx for Lustre was also synchronized with an S3 bucket to share files between the HPC cluster and the Windows workstations for post-processing the results.
Windows workstation for post-processing GEOSX results.
- Windows workstation: along with each cluster, a Windows workstation running on a g4dn.xlarge (4vCPUs, 16GiB and an NVIDIA T4 GPU) instance was available, and accessible through DCV sessions.
Students had access to the cluster through classical means: SSH connection to the frontend node, a web portal (EnginFrame) to launch DCV sessions on the Windows instance, and finally, they also had access to the AWS Console to interact with the S3 bucket dedicated to their team (for security reasons, they only had access to their team’s bucket, and no other services).
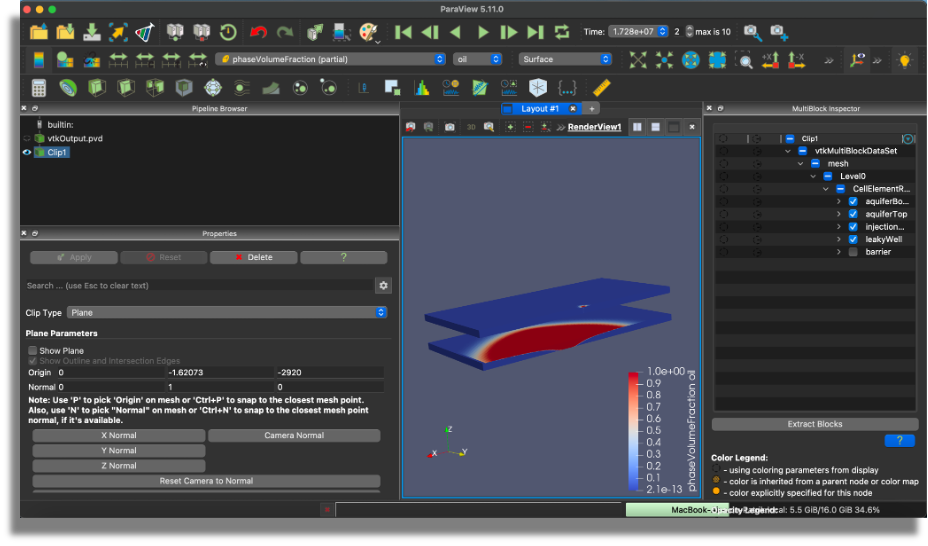
Example of post-processing a GEOSX simulation on the isoThermalLeakyWell test case obtained by one of the team.
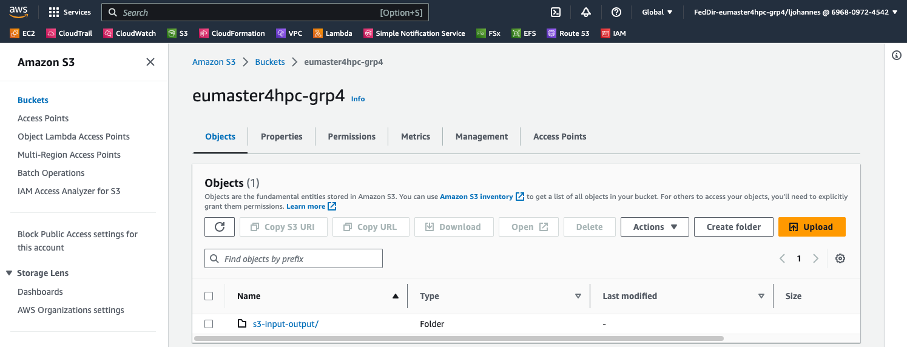
Dedicated S3 bucket per team. Synchronized with FSx for Lustre.
The administrators and the teachers had access to all the clusters to help the students when needed.
The whole platform was centrally managed by UCit through Cluster-in-a-Box (CIAB): from the initial deployment just before the hackathon started, the management of the teams in a centralized Active Directory, and the termination of all services and cleanup of the platform. All of this is completely transparent to both the students and teachers, and was done very quickly and easily on UCit’s side with a set of configuration files and the CIAB automation.
How were the clusters themselves used?
Since clusters have been deployed with CCME, we automatically get access to accounting information about all the jobs that the students have submitted. Though the target of the Hackathon wasn’t only on running simulations (the biggest work was on benchmarking the nodes and compiling GEOSX), it is still interesting to understand how the provided resources have been used.
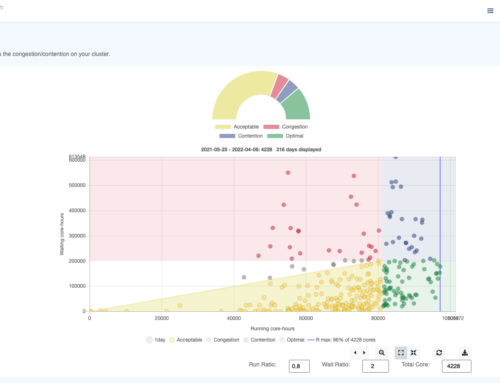
CCME automatically collects Slurm accounting logs, that we can then ingest in OKA (see our other post on this topic for more details), our data science platform for HPC clusters. All teams managed to run GEOSX simulations on multiple nodes, trying to make it scale from 2 to 10 nodes. Most of the jobs have been submitted on the last day of the hands-on session, as most of the initial work was to benchmark an hpc7g instance (using HPL, Stream and HPCG), and then to compile GEOSX.
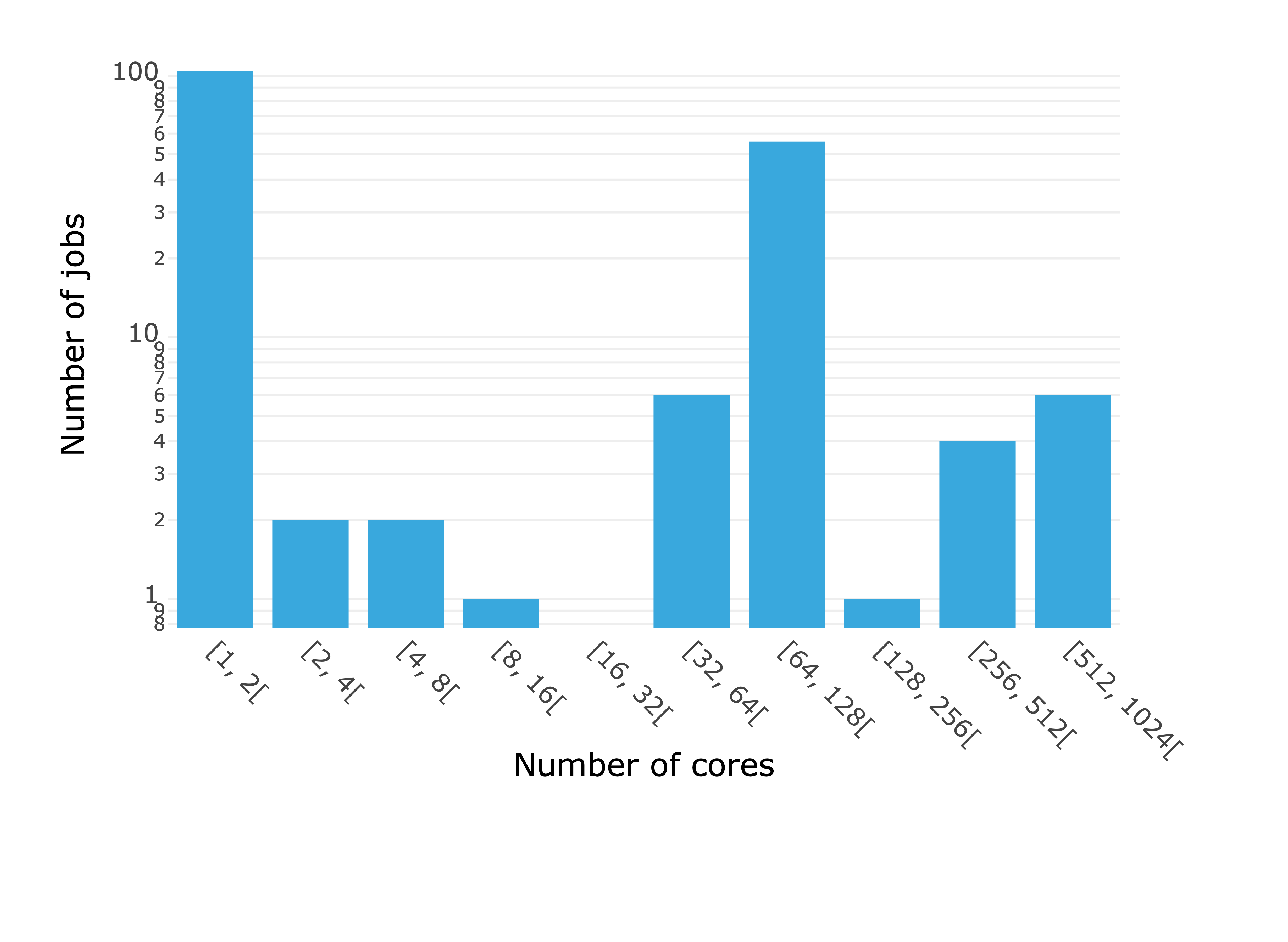
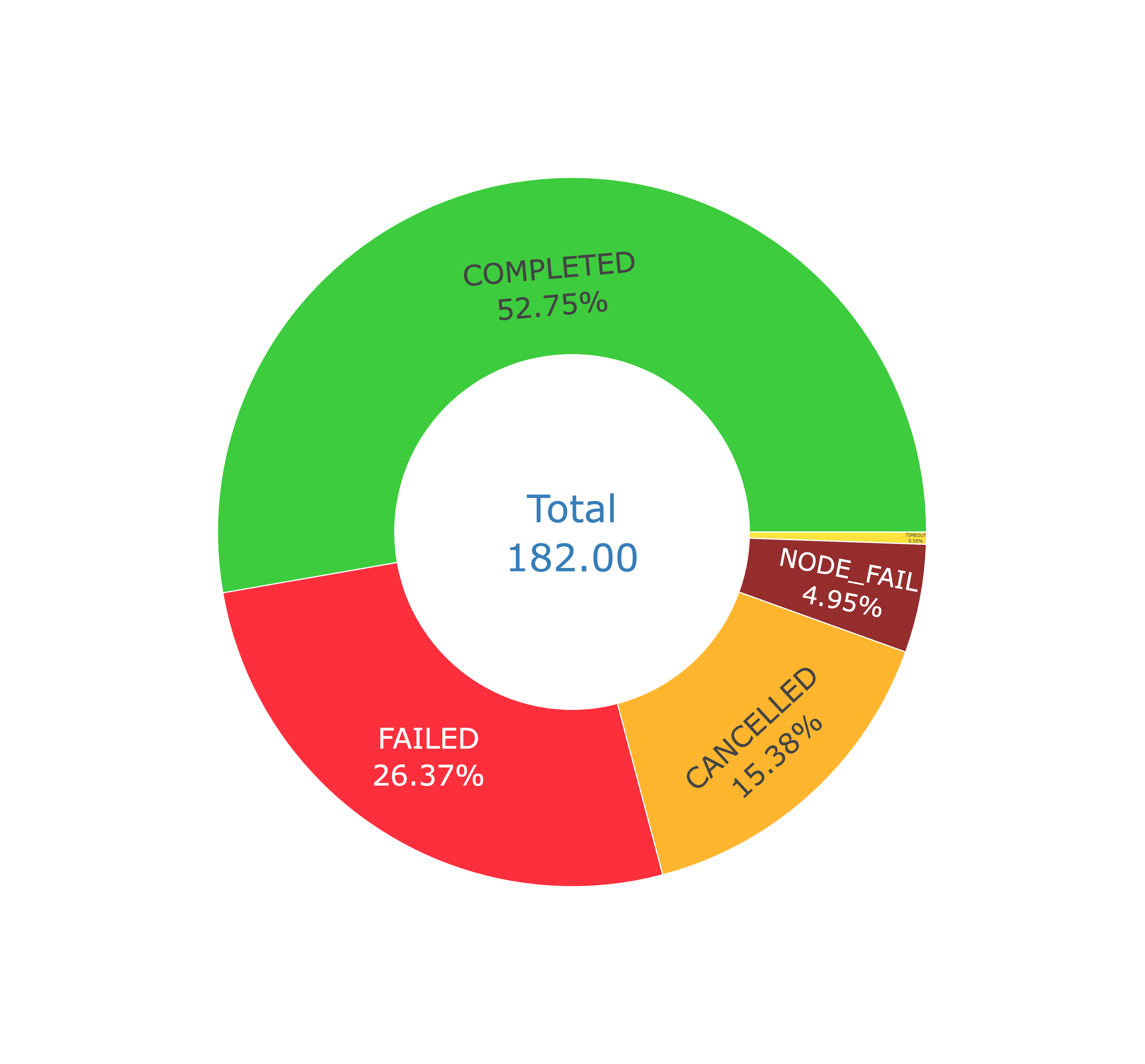
Example for one of the team: Cores allocation & Number of jobs per Job status visualized in the OKA Suite.
All in all, not all the available resources have been used. This is expected in a non-production environment, and quite common in such training environment. And this is where the auto-scaling of the compute resources is important: instances are started only when needed, and terminated after a short period of time when the instance is idle (no jobs are running on it). In the end, thanks to CCME and CIAB, you only pay for what you consume.
Key success factors for this event
The success of 2023 edition can be attributed to several key factors.
- The enthusiastic and positive engagement of the students played a pivotal role. Their passion for HPC and their willingness to collaborate and challenge ideas created a vibrant and productive atmosphere.
- The active involvement of AWS and its partners significantly contributed to the event’s accomplishments. AWS provided essential HPC resources, while ARM offered valuable guidance on the porting process, incorporating tools like ACFL (ARM Compiler for Linux) and ARMPL (ARM Performance Libraries). NVIDIA and SiPearl shared their invaluable hardware expertise, and TotalEnergies brought their deep knowledge of GEOSX to the table.
- Another critical success factor was the use of effective HPC instantiation and administration solutions that facilitated seamless access to HPC resources for the students and easy monitoring for admin teams throughout the event:
- Efficient cluster instantiation with Cluster-in-a-Box (CIAB) and Cloud Cluster Made Easy (CCME)
- Seamless remote access to the machines with NICE’s EnginFrame and DCV solutions
- Analysis of detailed resource usage with the OKA Suite
These solutions administered by UCit played a pivotal role in not only streamlining resource allocation and monitoring but also optimizing resource usage, ensuring that students could make the most of their HPC experience. Collectively, these factors created an environment of collaboration, learning, and innovation that defined the success of the 2023 Hackathon.
Acknowledgements
A heartfelt appreciation goes out to Kevin Tuil (from AWS), Conrad Hillairet (from ARM), Benjamin Depardon, Jorik Remy (from UCit), and Francois Hamon (from TotalEnergies) for their outstanding efforts in orchestrating the infrastructure and ensuring the secure porting of the GEOS(X) code to AWS EC2 Hpc7g instances, as well as their invaluable support to the participating student teams. This summer school event, spearheaded by Ronan Guivarch (Professor at Toulouse INP), Arnaud Renard (Director of ROMEO Super Computer Center), Christophe Picard (Professor at Grenoble INP), and Stéphane Labbé (Director of SUMMIT at Sorbonne universities), received substantial backing from a diverse ecosystem. Gratitude extends to AWS, alongside its HPC partner networks, including NVIDIA (represented by Gunter Roeth), UCit, Arm, and SiPearl, for their enthusiastic support. The active involvement of Francois Hamon from TotalEnergies added immense value to this endeavor.