Optimizing HPC Clusters: Addressing Congestion and Contention with OKA
In the realm of High-Performance Computing (HPC), the intricacies of cluster management often lead to congestion and contention, hindering optimal performance. To mitigate these challenges, UCit introduces OKA Core, a robust framework tailored to identify, analyze, and resolve issues within HPC clusters. By synergizing OKA Core with OKA Predict and OKA Shaper, administrators can enhance resource allocation, streamline job submissions, and efficiently address congestion and contention problems, ensuring superior cluster performance and user satisfaction.
Understanding Congestion and Contention on HPC clusters
High-Performance Computing (HPC) clusters stand as the backbone of scientific and industrial computing, enabling users to process complex simulations and data analysis. However, within these intricate systems lie two common challenges: congestion and contention. These issues pose significant hurdles for administrators striving to maintain optimal cluster performance and deliver high-quality service to users.
Congestion arises when a cluster underutilizes its resources, leaving jobs waiting in queues despite available computing capacity. It simply means that you still have resources that could be used for those jobs in queue but for whatever reason, the cluster does not allocate these jobs to free resources.
On the contrary, Contention occurs when the cluster operates at peak capacity, yet fails to meet the surging demand for resources, causing queues to pile up.
How to identify Congestion and Contention
To properly identify Congestion and Contention states, we will examine two specific metrics:
- The first, on the horizontal axis, involves the running CPU hours—this denotes the amount of CPU time allotted to jobs, which isn’t available for other tasks.
- The second metric is the waiting CPU hours, which represents the accumulation of queued CPU time requested by jobs.
These metrics help in establishing two defined targets:
- The first target is the minimum cluster load, aiming for optimal efficiency and maximal capacity utilization. For instance, setting an 80% threshold indicates the desired allocation of resources on the cluster at any given time.
- The second target to establish is the maximum waiting load, which predominantly concerns the user’s perspective. The aim is to maintain enough jobs in queue to keep the cluster busy, but not too much in order for users not to wait for too long for their jobs to start and ultimately receive their simulation results in time.
The defined framework outlines four specific zones:
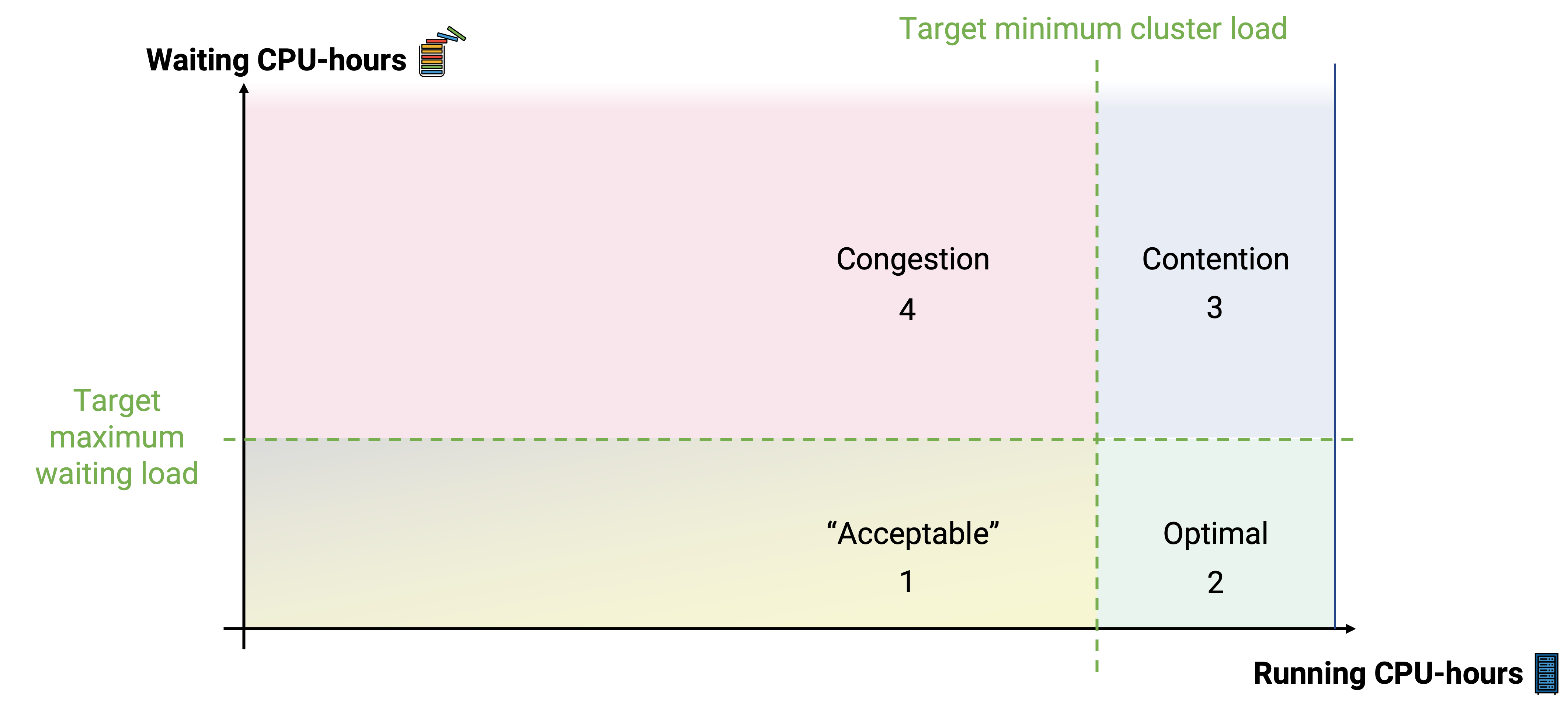
The bottom blue zone represents the optimal state, where the cluster operates above the minimum target load yet below the maximum waiting load. This signifies maximum capacity usage without excessive queue waits.
The acceptable state, a grayish-yellow zone, occurs when there’s a lower demand for CPU hours, leading to underutilization of the cluster’s capacity. It’s not ideal as it may indicate overprovisioning or low demand periods like weekends.
Congestion and contention represent the top right and left zones, respectively. Congestion occurs when the cluster consistently operates in an overloaded state, while contention happens during peak demand periods or specific requests such as very large jobs (with lots of CPUs requested).
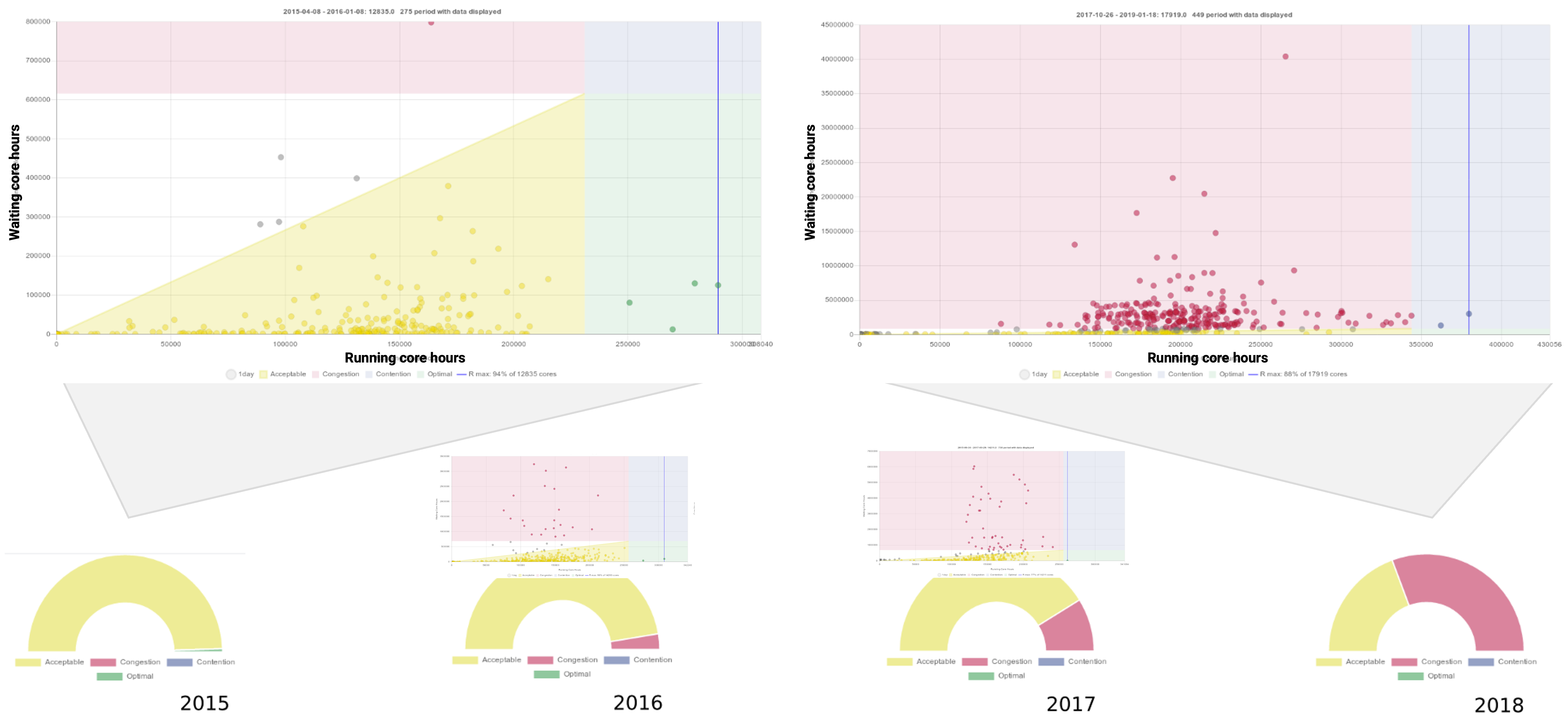
An example of congestion reveals a cluster’s evolution from an acceptable state at the start to a congested state over time, indicating increased demand surpassing optimal use:
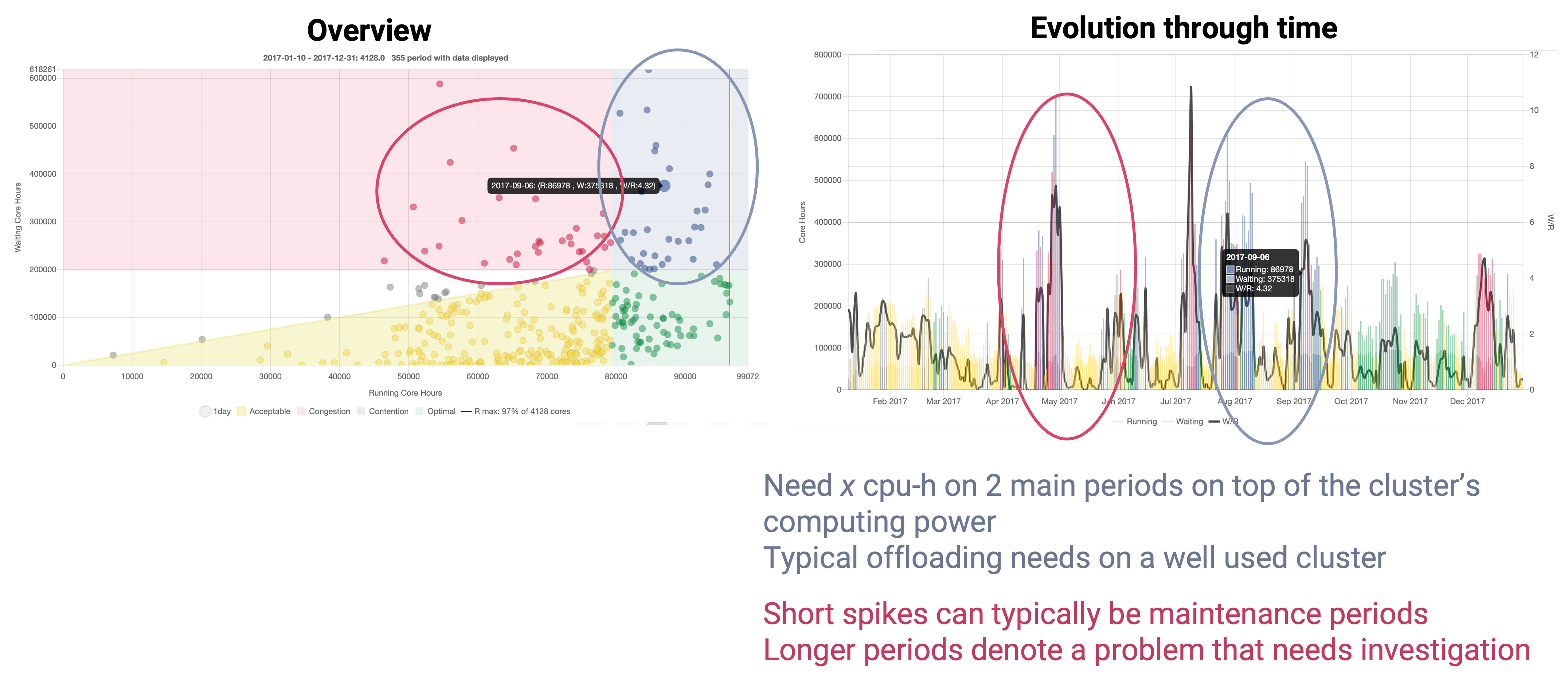
Another cluster demonstrates more balance across the zones but faces contention, notably during peak periods like summer. These peaks might signal a need to offload jobs to external resources or could result from new users’ job submissions or maintenance periods, requiring further investigation:
For HPC administrators, achieving an ideal balance between the cluster’s capacity and users’ demands is pivotal. This is where UCit’s OKA Core framework stands as a tool of choice in navigating these challenges. By delving into the behavior of users and jobs within the cluster and scrutinizing logs (accounting, applications, etc.), OKA Core offers insights into identifying problematic events and prescribing solutions.
Unveiling the OKA Core framework: Real-world encounters with congestion and contention
The OKA Core framework empowers administrators with a suite of customizable tools designed to decode the labyrinthine behaviors within HPC clusters. At its heart, OKA Core assimilates data from various sources, including job schedulers like SLURM, LSF, PBS, SGE, TORQUE, and any additional logs you can gather about your jobs. This treasure trove of information, in turn, fuels OKA Core’s ability to present hundreds of Key Performance Indicators (KPIs) vital for understanding cluster operations.
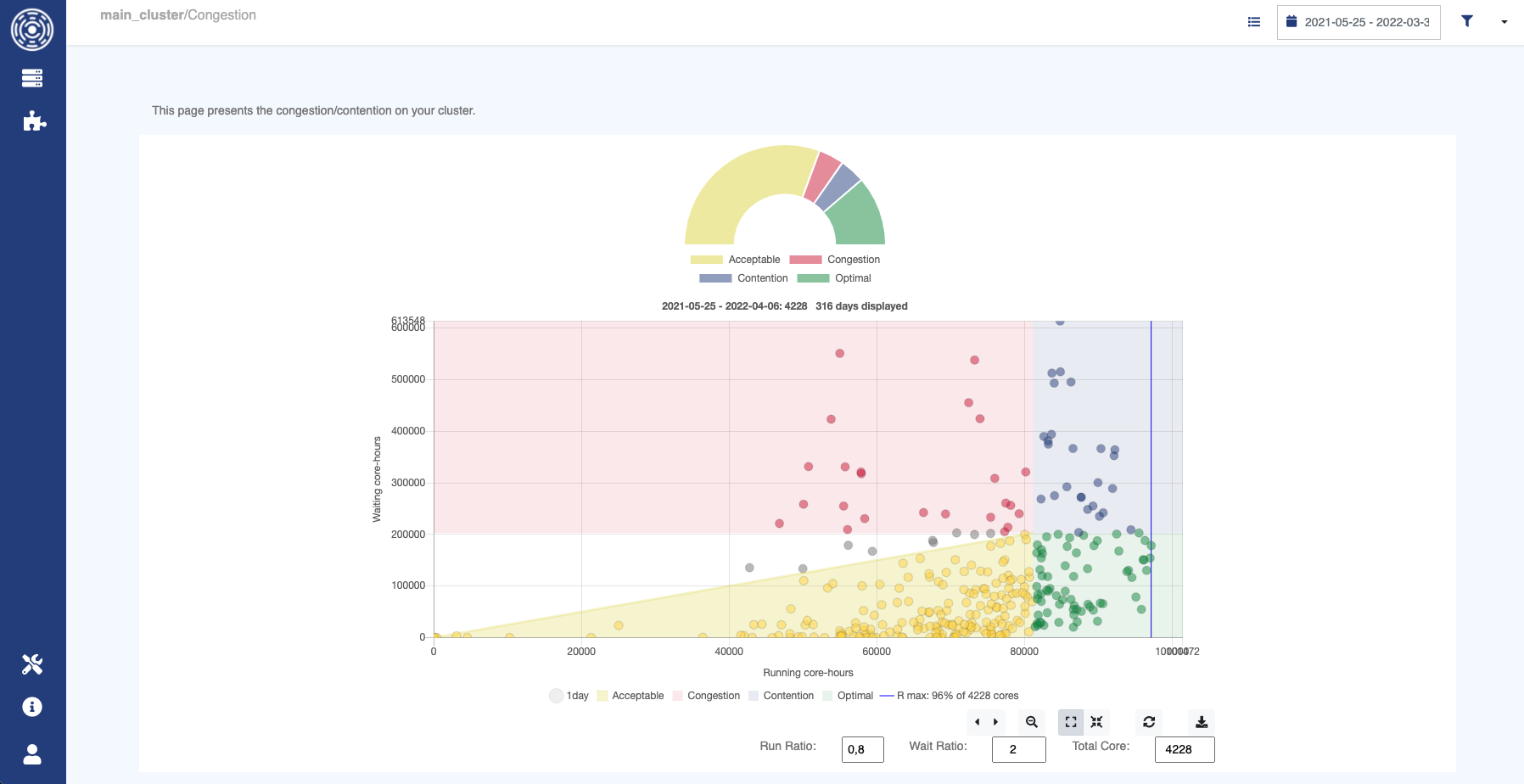
Through a comprehensive presentation and analysis of this data, OKA Core unveils the nuanced dynamics of the cluster, pinpointing congestion and contention states. It categorizes these states into four zones: optimal, acceptable, congestion, and contention, providing administrators with a visual representation of the cluster’s health.
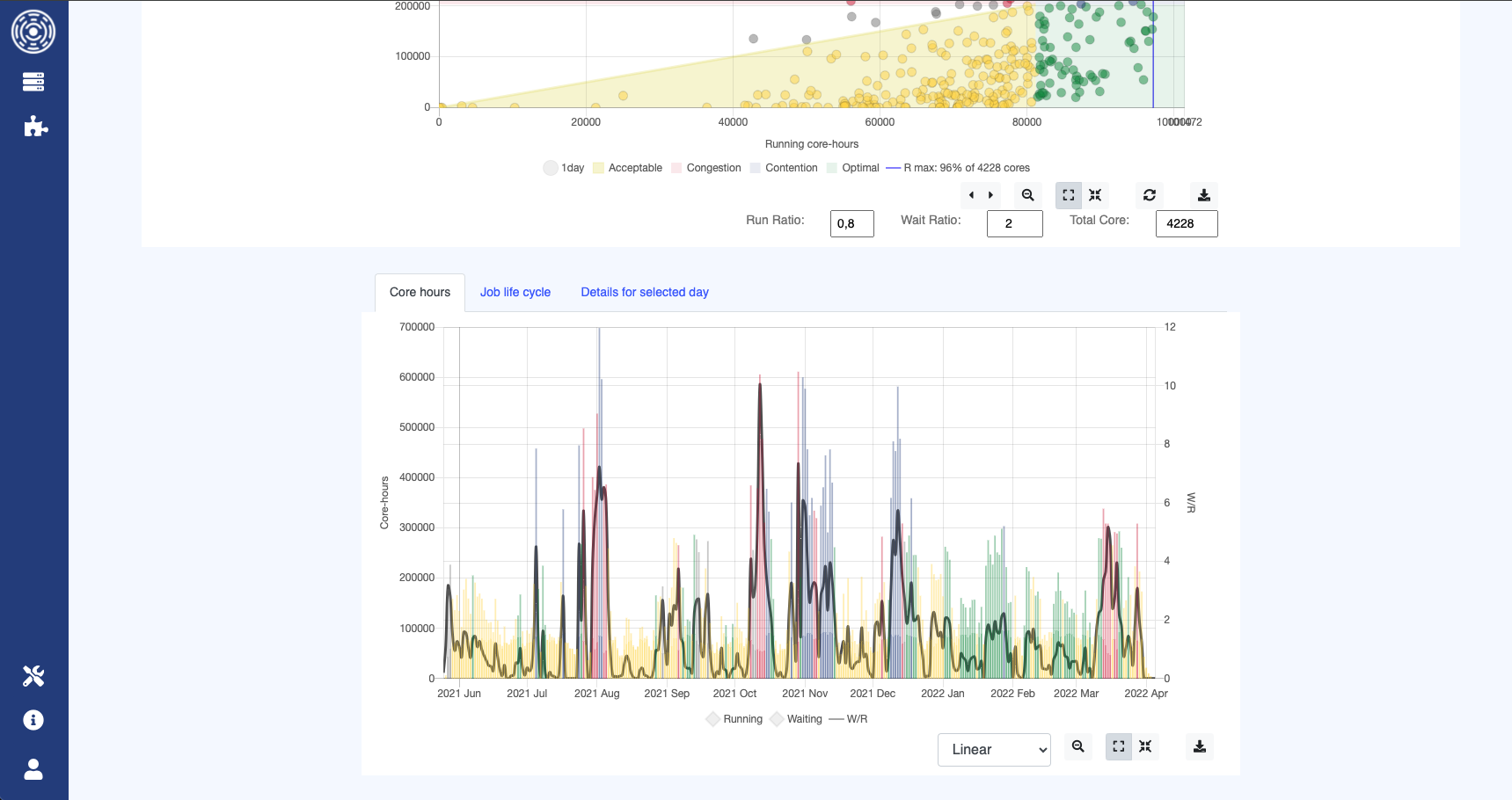
OKA Core generates an analysis based on defined parameters like maximum and minimum cluster load and rate ratio. For instance, with a set minimum cluster usage of 70% and a waiting-to-running ratio of 1.5, you can visualize four zones: optimal, acceptable, congestion, and contention. This analysis might reveal 40% optimal, 30% acceptable, and significant contention instances. It provides a day-by-day overview of the cluster’s computational life for a year, letting you click on specific dates to delve deeper into that day’s activities—such as CPU hours delivered, jobs waiting in the queue, and job types. This tool helps understand congestion and contention situations, and other plugins can offer detailed insights into resource consumption, user activity, and job specifics:
How to solve the Congestion-Contention paradigm?
Addressing congestion and contention involves several potential solutions. One approach is tweaking the job scheduler configuration, adjusting partitions or policies affecting job speed. Resource sharing can optimize allocation, and for contention, adding resources or utilizing external cloud resources during peak demands can help.

To tackle congestion, optimizing job submission parameters is crucial. Users often request more resources than needed—like execution time, cores, or memory—leading to longer queue times. Overestimating job runtime or requesting excessive memory can delay job scheduling and result in inefficient resource use. Optimizing parameters like runtime and memory allocation prevents these issues, ensuring faster job execution and resource efficiency.
And this is where OKA Predict can help tremendously.
OKA Predict: Forecasting the future of jobs to avoid Congestion
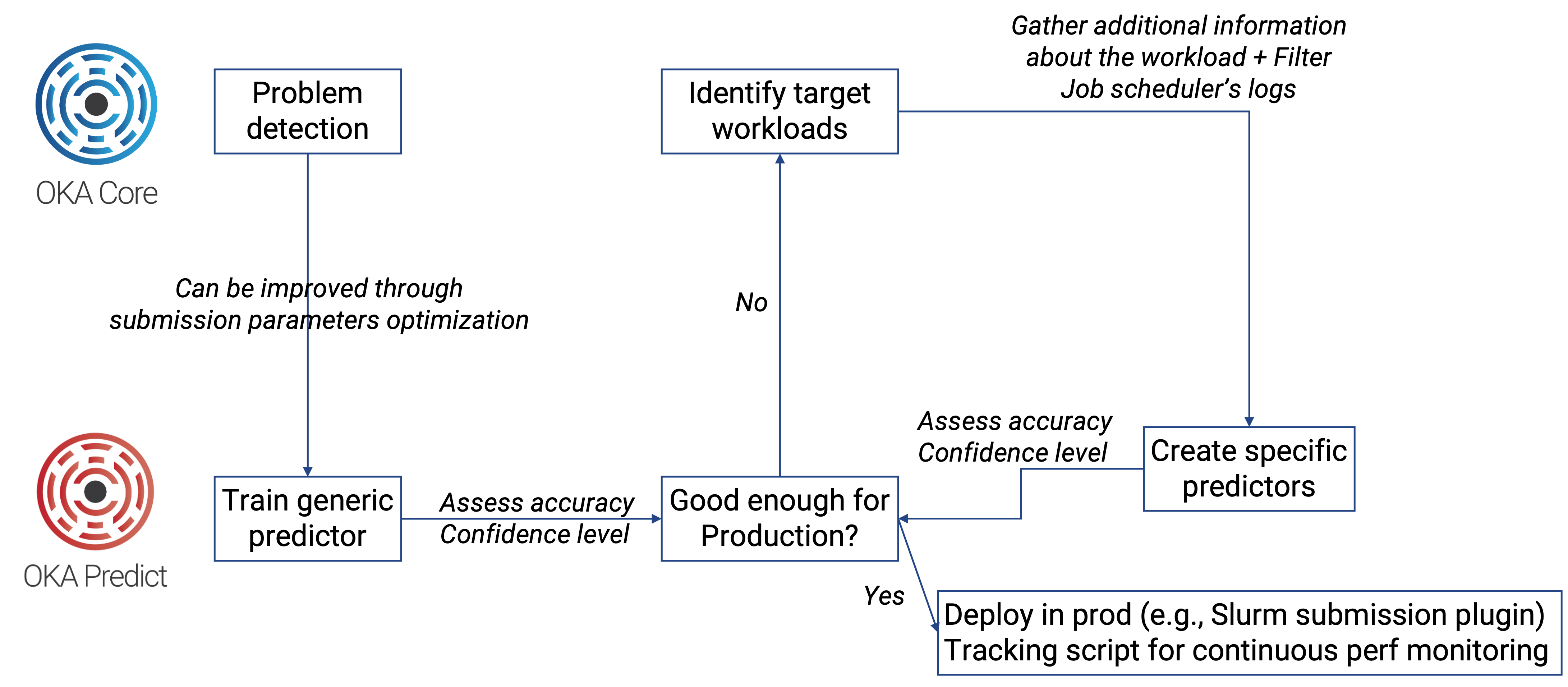
To combat the issues of inefficient job submissions that contribute to congestion, OKA Predict emerges as a promising solution. This machine learning-driven tool ingests cluster logs and employs various algorithms to predict crucial job parameters, including execution time, memory consumption, potential failures, and even estimated waiting times.
Through a multi-step process, OKA Predict’s predictive abilities are honed, beginning with the analysis of job scheduler logs. Subsequently, the tool undergoes iterative refinement, incorporating specific workload information to enhance accuracy.
OKA Predict: a real-life use-case with NAMD
For instance, the tool might target a specific application like NAMD (Parallel Molecular Dynamics software) to predict execution time and memory usage more accurately.
We aimed to predict the behavior of NAMD jobs on our cluster, focusing on execution time and memory consumption. Initially, using only job scheduler logs, our predictions were around 30% accurate—a far cry from ideal. To enhance accuracy, we included specific NAMD job details like problem size and job steps, increasing prediction accuracy by nearly 20%. Despite this improvement, our predictions were still not perfect, reaching about 50% accuracy for execution time.
OKA Shaper: Planning for Cloud resources to optimize Contention
One good way to resolve contention issues is to use cloud resources. The of OKA SHaper is not on actual deployment of HPC resources in the cloud but on assessing its feasibility and cost-effectiveness. It is crucial to consider if moving to the cloud aligns with customers’ budget and project schedules. To aid in this evaluation, our OKA Suite comes with a tool called OKA Shaper.
OKA Shaper analyzes your cluster logs to estimate the cost of running specific workloads on the cloud. By simulating various strategies and instance types, it projects costs similar to on-premises HPC clusters. It assesses compute nodes, storage, additional services like visualization tools, and data transfer expenses. In essence, these tools and processes help comprehend cluster issues like congestion and contention, detect areas for improvement, and offer insights to enhance cluster productivity and service quality. Gathering and storing cluster and job metadata is key to effectively use these tools for analysis and optimization.
As we can see in the OKA Shaper snapshot below, we are able to quickly visualize what it would take to take some of our workloads to the cloud (in the case of an AWS migration for example):
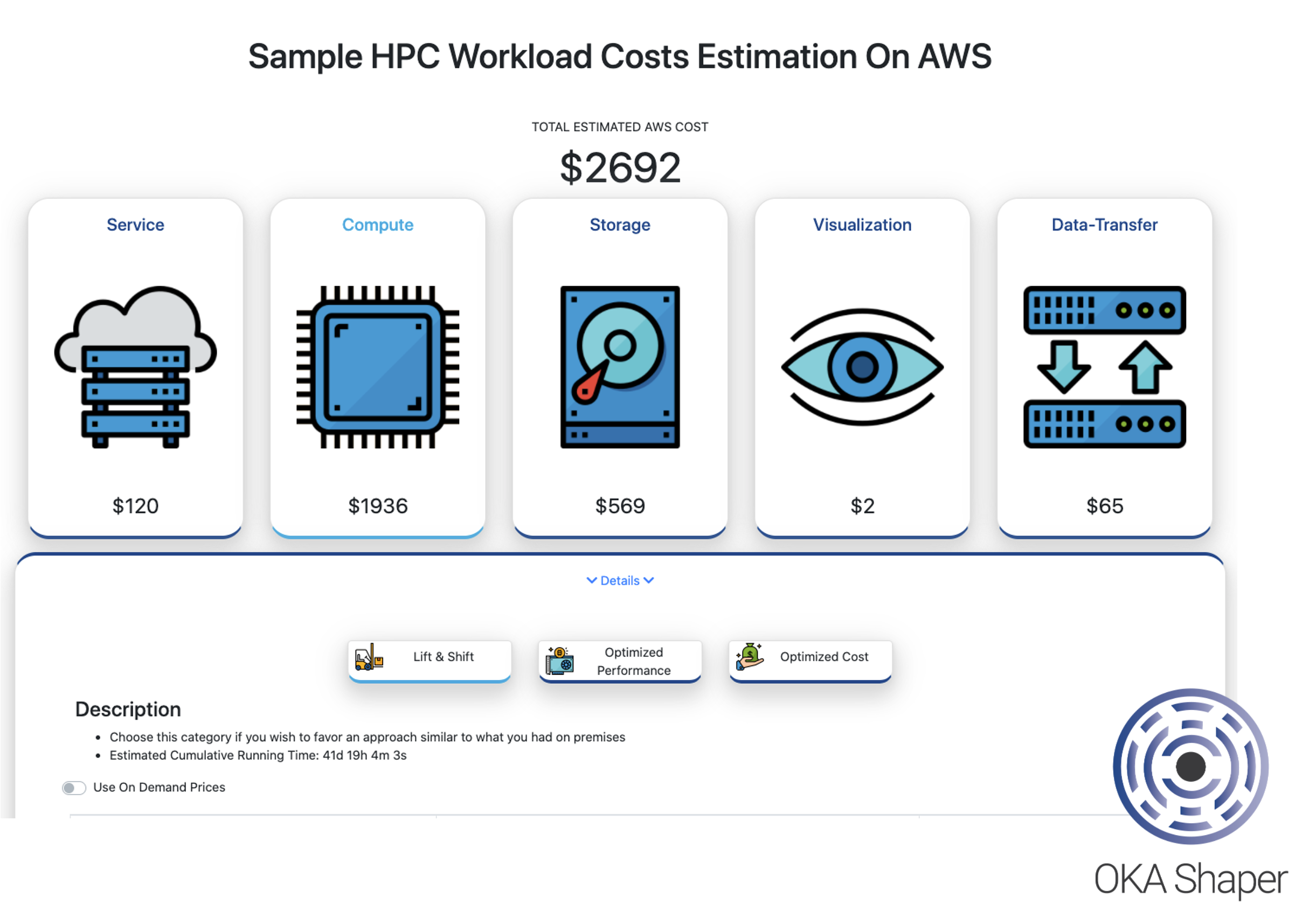
OKA Shaper allow admins to:
- Select workload from groups of users/application/job size…
- Estimate budget for moving the workload to the cloud based on multiple strategies.
- So they can then train predictors for each target infrastructure to route jobs with OKA Predict, based on their policies.
Orchestrating optimal cluster performance
Making informed decisions to reallocate resources, adjust scheduling policies, or even optimize hardware configurations to alleviate congestion or contention zones is a key component of an administrator’s daily occupations.
The symbiotic relationship between OKA Core and OKA Predict becomes the cornerstone of ensuring this optimal cluster performance. OKA Core uncovers congestion and contention points, while OKA Predict forecasts job parameters, combining forces to proactively improve congestion. Armed with OKA Shaper, admins can push the analysis even further and anticipate ways to further eliminate contention issues by moving some computations to the cloud, for example.
Having tightly integrated tools like these, all working towards the same optimization goals and making in-depth use of cluster logs provides an undeniable advantage in cluster administration endeavours.
Final thoughts
The journey through the complexities of congestion and contention within HPC clusters unveils a fascinating world of analytics, predictive modeling, and the quest for optimal resource utilization. UCit’s OKA Suite framework, bolstered by the predictive abilities of OKA Predict and Cloud resource-assessment insights of OKA Shaper, heralds a new dawn for administrators as well as users, ushering them into an era of proactive and insightful cluster management.
This union, augmented by machine learning and AI, presents a positive glimpse into the future—a future where clusters not only meet demands but anticipate and preempt them, ensuring an uninterrupted quest for scientific discovery and industrial innovation.